
Structured data in contracts and open AI algorithms
Explore the future of contracts with structured data and open AI algorithms, driving efficiency, risk management, and innovation in the legal industry.

By Simon Black
Co-Founder and Chief Commercial Officer Lexical Labs
I always enjoy the New Year period for its festive fun, peace, family time and predictions for the next year. Legal tech is moving so fast that a year can pack a lot of progress.
My favourite site for predictions is the Artificial Lawyer and this year was no exception. So many experts brimming with ideas, aspirations and doses of reality. The common theme is that we should all continue to push the boundaries.
I was particularly struck by the aspirations of Addleshaw Goddard’ respected head of innovation Kerry Westland on the linked issues of making contracts more structured and making AI more open. These are really important areas which need an open debate. Whilst I mostly agree with Kerry, I thought I would add my thoughts.
Structured data in contracts
Kerry’s aspirations:
‘We’d like to see more clients successfully implement new contracting strategies, both using technology and using better drafting and process. We’d also like to see them lean on their law firms more for support, guidance and technical assistance for this type of work, both before and after decisions about approach and strategy have been made.
Whilst looking at this with clients we’d also like to see the legal industry reduce its reliance on Microsoft Word and make strides towards being able to structure data from the outset and, therefore, in the long term, start to reduce reliance on AI-powered document review tools which simply extract and structure data from unstructured documents.’
My thoughts
I’d agree the industry wants to move quickly to contracts that contain much more structured data. To me the ideal business contract should be easily drafted, read and actioned by a business person, lawyer and a machine. The business person and the lawyer have slightly different priorities. The former is more focused on commercials and day to day management; the latter on drafting, detailed review and strategic risk management. That said, speed and outcome are equally important to both.
The machine serves both as it can present data insights and analysis to both a business manager and a lawyer. Or it could execute the contract automatically using software (smart contracts). Both provide potentially huge time savings, better risk management and (importantly) improved mental health.
Contracts currently contain mostly unstructured or semi-structured data. Machines can extract data and provide insights but only indirectly using NLP and Machine Learning techniques (which either classify and label the contracts or work out commonalities or anomalies). This translation layer costs time and money because of the data collection, AI model training and vendor fees involved (although a lot less than the old way of having someone manually review contracts). Moving to structured contracts reduces the need for this ‘translation layer’
This white paper on structured data contracts published by the UK Legal Schema provides the best explanation I’ve seen of the benefits of moving to structured contracts. https://technation.io/wp-content/uploads/2021/06/LegalSchemaFinal.pdf
In essence, structured contracts are more easily read by machines and provide the best basis of moving towards smart contracts and digital assets.
Most of us can visualise how a lot of commercial terms can be structured. For example, the term of a contract, the interest rate of a loan or the payment terms. Below is an example of how these terms can be presented as structured data.
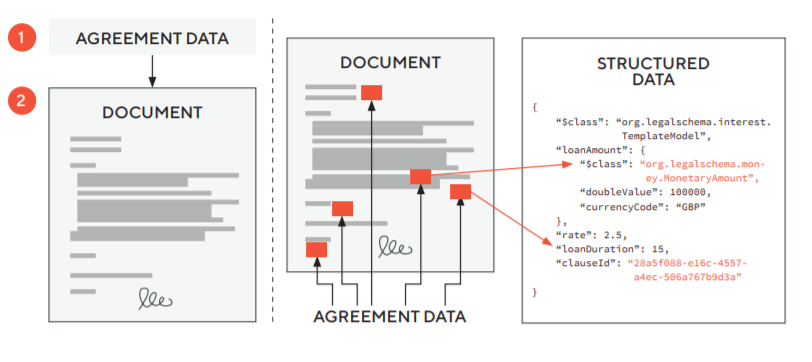
It will be more challenging to structure the ‘legalese’ - the important terms of a contract that deal with allocating responsibilities and risk. For example, a basic liquidated damages clause might be easily presented as structured data (target completion date, daily rate and overall cap) but it is less easy to present the exceptions (force majeure, change orders and instructions given by the client, breach by the client). These exceptions are important to understand the clause as a whole.
Over time, I’m confident that we can find a way of presenting such provisions as structured data, both by (i) standardising contract wording (led mainly by industry bodies and open sourced projects like OneNDA - https://onenda.org/ - but also law firms) and (ii) adopting a common data format for representing this wording on a machine readable way.
But I disagree with Kerry that we’ll be reducing reliance on AI tools in this increasingly structured world.
- First, many AI tools aren’t simply ‘extracting and structuring data from unstructured documents’. Instead, they are often pulling together the provisions across a contract in the way a trained contract reviewer would and (sometimes) comparing these provisions to requirements of the client or industry standards (by analysing the contract against a larger data pool).
- Secondly, the ‘NLP translation layer may be reduced but it won’t be eliminated because of the challenges of presenting legalese as structured data.
- Thirdly and crucially, the AI tools will become potentially much more powerful as clients focus less on whether they have correctly understood the contract and more on what data insights they can provide.
Answering questions objectively like ‘are we spending too much time and money negotiating our contracts because we are not aligned with industry standards’ or ‘how do our contracts inform our company’s business strategy - for example, are we more profitable and capital efficient if we lease rather than purchase key assets?’. AI tools will connect a contract to other data sets which help answer these questions.
‘Open AI algorithms and open access to contract data’
Kerry’s aspirations
I’d like to see more AI tools come out with an honest assessment of their ML algorithms, whether through moving to something like the new Google doc AI and giving up on their own ‘closed source’ versions, or coming out and helping customers understand the gaps in their data a bit better. I’d also like to see a concerted effort to pool data together to improve more open source algorithms through law firms and clients allowing better access to documentation and a push towards a better open source community.
My thoughts:
I completely agree with the need to pool contract data so that NLP, ML and other algorithms can be better trained for the benefit of all. I can see this happening by a combination of sandbox experiments, the use of anonymisation technologies and legal and regulatory developments. The key challenge is overcoming concerns about client confidentiality. The pooling of data should benefit the whole ecosystem of small and large enterprises,law service providers and technology vendors. It should cut the cost of legal review for all and spur innovation.
A truly open source of contract data is arguably unrealistic in the short term and a more likely approach is increased but still private pooling of data amongst a club of participants. This has benefits but risks benefitting mainly larger enterprises, legal service providers and technology platforms who are ‘in the club’. We need a healthy discussion about how to avoid this.
Turning to the issue of closed vs open sourced ML algorithms. I must admit I find this area very complex. Users often would like to understand (i) the data set on which the technology has been trained (including its gaps and biases) and (ii) how the algorithm then works on data outside of the training set. The suggestion is that AI vendors should either move to more ‘open systems’ such as Google Doc AI (and its recent offspring Google Contract AI) or help customers understand the gaps in its dataset.
The potential advantages of using a set of common classifiers like Google Doc AI is a common baseline about how a document may be classified. However, a classifier is a product of several things: (1) the data used to train it (and what is used for training vs testing) (2) the algorithms it uses (eg word vectors, transformers), (3) how the algorithms are trained (how long + with what settings). A common classifier would mean having these elements the same (so that you know it would run the same way each time). The problem is that Google Doc AI is not transparent on any of these fronts. However, there is innovation and debate about the best way to train things best left to the experts, so there could be a way of groups training their own models and sharing their accuracy against the datasets as a way of showing their improvements. A centralised approach like this would be complex to manage however: there would need to be a way for entities to add extra datasets and augment existing ones. There would need to be a full time staff ensuring the quality and relevance of the data.
Noah Waisberg, (Co-Founder of Zuva and previously Co-Founder of Kira) makes a case for choice, competition and innovation well in his blog post on Google as a competitor (https://zuva.ai/blog/having-google-docai-as-a-competitor/) . Google currently comes with 21 pre-trained topics or smart fields (albeit with the capacity to increase this dramatically); Zuva has 1,200.
Our own Tiro system focuses mainly on helping companies review and negotiate their repeatable contracts (and less on bulk analytics and diligence exercises). The way we read and assess contracts is both a result of our pre-trained AI but more importantly an expert system that is capable of analysing an issue in full, including which way obligations flow, exceptions and key values. See below for an example summary output where the system has identified and summarised 3 different caps on liability in a contract. This type of output is possible by weaving various AI and other technologies into a coherent user experience. Because of the techniques involved, we need less contract data to train up a particular issue.
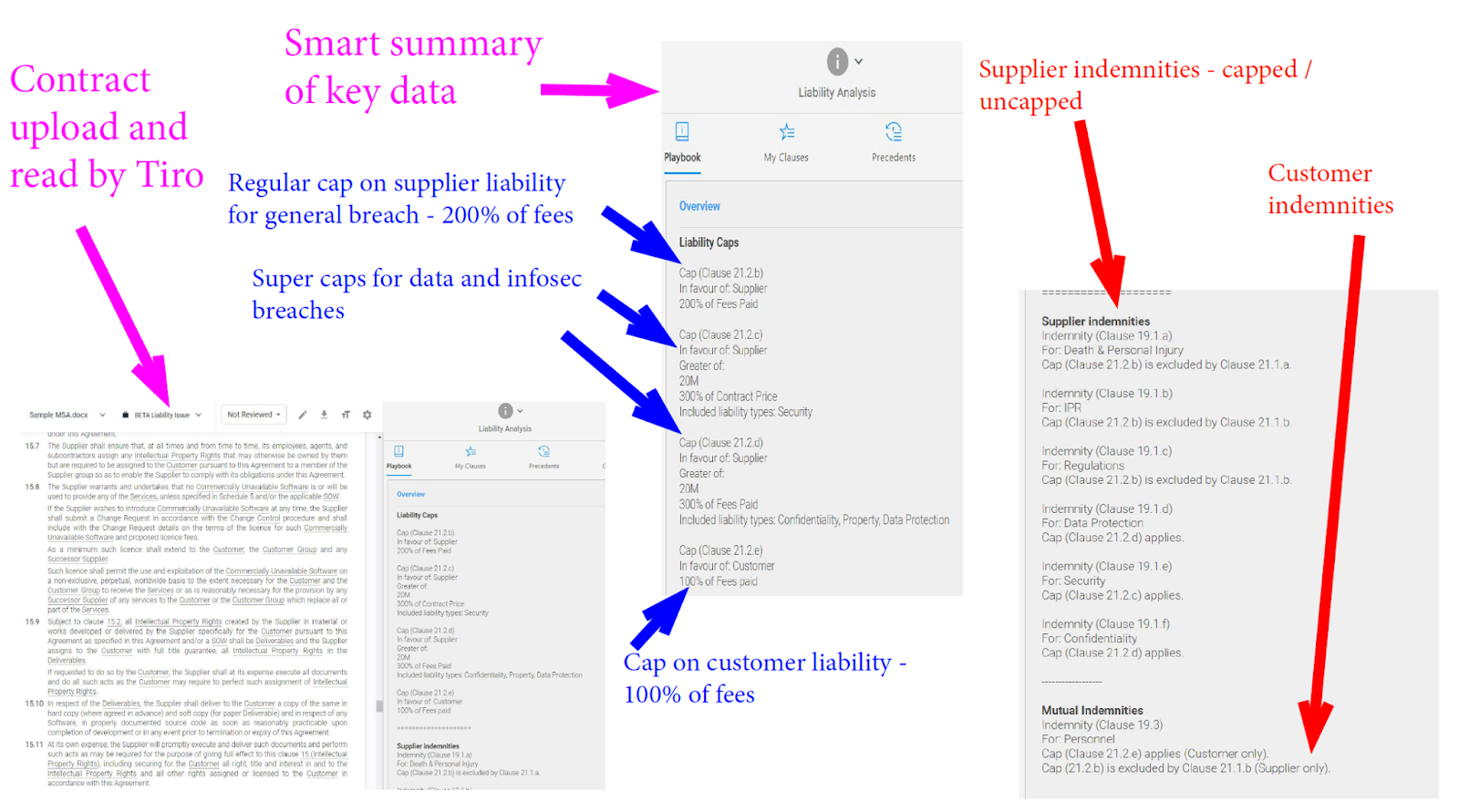
So overall, the market is better served by AI vendors innovating and there being choice for customers rather than converging around a single classification system that a Google Doc AI may offer.
I think Kerry has a point that AI vendors should therefore be more open about their training models (her alternative approach). The question is how and our experience is that flexibility of approach is key. Different clients have different needs. If a client has machine learning specialists or data scientists, we would share key data on our training models such as the size of the training set, how we determine accuracy and other information that give the insight necessary to feel comfortable trusting the system. If the client has advanced legal engineers, we offer the ability to train new models in our system and set-up and maintain playbooks. Ordinary users want the ability to train the system (either correct mistakes or teach the system a new concept) with a simple user interface. Some customers come with a set of key words they care about and want to ensure that these are brought to their attention regardless of whether an overly smart system thinks otherwise!
Obviously, all of this is done within the confines of maintaining client confidentiality and data security. And all of this would be much easier if there was more open access to contract data.
Most of our clients are companies and managed service providers (including some law firms with managed service offerings) reviewing specialist contracts. We tend to get less requests for information on our models and more requests for the client to build solutions. I’d be interested in hearing more from Kerry and other law firms about what would help them better understand the solutions in the market and how to maximise their potential. I can see this being a great discussion over a webinar or at a conference.
Other Posts
Browse some related whitepapers

Agentic AI and the Convergence of Contract Review and Document Automation

Why Contract Review Automation Is Lagging — And What We Can Do About It

Initial views on Recent Developments at OpenAI

Automated Contract intake and triage
Tendering - Pass the Parcel - Who's in charge of the contract?

Why procurement contracting often seems harder than sales - but shouldn’t be!

Why contract playbooks are essential (and easier than ever to set-up)

Reimagining Law - The automated M&A deal?

How Fast Growing Digital Businesses can Harness the Power of AI Contract Review

Lexical Labs automatically risk scores your contracts

Contract triage and pre-screening using Automated Contract Review

A Contract Management Blueprint for Agile Businesses

Automated review of Customer Contracts – Stantec Case Study

7 questions to ask your AI contract review vendor

7 Trends Transforming Contracting and Legal Professionals in the Engineering, Construction and Advanced Manufacturing Sectors

An AI Engineer’s Personal Journey Into Law

Are you feeling the pain of Third-Party Paper?
Join our community and start optimising your legal operations.
Book a demo using the contact form below, and we can show you the power of Tiro up-close and personal.
Sign up for our newsletter
No spam, we promise! Just the occasional email with product updates and value from our whitepapers.